单证处理
概述
单证处理是货代智能 Agent 的核心能力之一,由 document_extraction 智能体类型承载。当前链路已经从“上传 PDF 并下载 JSON”升级为完整的单证识别工作流:
- Demo 端支持拖拽、粘贴、选择
image/*与.pdf - 后端统一归一化为可提取、可预览的文档资产
- 提取结果会持久化作业摘要与字段级审核状态
- Demo 端承担字段审核工作台
- Admin 端承担概览、队列、异常追踪与跳转
当前支持的输入类型:
- PDF 单证
- 图片单证(
image/*)
端到端流程
flowchart LR
A[Demo 上传或粘贴图片 / PDF] --> B[创建 extraction job]
B --> C[归一化源文档资产]
C --> D[pdf_processor / data_extraction / validation]
D --> E[写入结构化 JSON]
E --> F[生成 summary / field reviews / issue list]
F --> G[Demo 工作台字段审核与字段历史查看]
F --> H[Admin 概览与队列]
G --> I[字段级 PATCH 持久化与 revision ledger]
I --> F架构设计
识别链路仍然复用 document_extraction runtime,但职责已经拆成四层:
| 层级 | 作用 | 主要位置 |
|---|---|---|
| Demo intake | 统一接收拖拽、粘贴、文件选择 | demo-frontend/src/components/DocumentRecognitionWorkspace.jsx |
| 识别执行 | 创建 job snapshot、解析 runtime、执行提取与校验 | ai_service/document_recognition/application/services/document_recognition_orchestrator.py, ai_service/document_recognition/infrastructure/runtimes/* |
| 交互审核 | 源文档预览、bbox、字段接受/修正/标记 | demo-frontend/src/components/Recognition*.jsx |
| Admin 运营 | KPI、队列、详情、跳转到 Demo 审核 | admin-frontend/studio/src/shadcn-admin/pages/document-recognition-page.tsx |
核心处理节点
| 节点 | 功能 | 说明 |
|---|---|---|
pdf_ingest |
初始化 | 创建上下文与文档元数据 |
pdf_processor |
资产归一化 | PDF 渲染为页面图像,图片输入会先被统一转换为 PDF 资产 |
data_extraction |
LLM 提取 | 视觉模型提取结构化字段与字段检测信息 |
validation |
数据校验 | 生成校验错误与后续审核信号 |
pdf_reporter |
结果汇总 | 产出结构化 JSON,供 review projection 使用 |
持久化模型
document_extraction_jobs
作业表保留原有对象存储键与执行状态,并新增识别运营与 runtime snapshot 字段:
source_media_typesource_filenameruntime_agent_idruntime_agent_version_idruntime_agent_type_snapshotexecution_mode(legacy runtime snapshot,仅用于持久化兼容,不属于/document-recognition/runs*canonical response)document_typereview_statussummary_jsonlow_confidence_countcorrected_field_countlast_reviewed_atlast_reviewed_by
document_extraction_field_reviews
字段审核表用于支撑 Demo 审核工作台和 Admin 统计:
field_keyfield_labelextracted_value_jsoncurrent_value_jsonconfidencepage_numberbbox_jsonreview_statusissue_codereviewer_note
作业级 review_status 由字段行自动投影:
- 全部待处理:
review_required - 部分已处理:
in_review - 全部接受/修正:
reviewed - 存在标记项:
flagged
document_extraction_field_review_revisions
字段历史不会回写覆盖旧值,而是追加到独立 ledger:
field_review_idjob_idrevision_numberprevious_value_jsonnext_value_jsonprevious_review_statusnext_review_statusprevious_reviewer_notenext_reviewer_notereviewer_identity_snapshotchange_sourcecreated_at
API 接口
列出可选运行时
GET /document-recognition/runtime-agents
返回当前被管理端显式注册为“可用于单证识别”的 Fusion agent 元数据。
查询识别任务列表
GET /document-recognition/runs
获取任务详情
任务详情现在统一走 canonical run surface,并返回审核工作台所需投影:
GET /document-recognition/runs/{run_id}
返回重点字段:
runtime_agent_idruntime_agent_version_idruntime_binding_snapshotsource_document_urlsource_pdf_url(仅 PDF,保留兼容)summaryfield_reviewsissue_listpreview_pagesreview_status
其中 field_reviews[] 默认只返回轻量 revision summary:revision_count、is_changed_from_extracted、last_revised_at、last_revised_by。
/document-recognition/runs* 的 canonical payload 不再返回 execution_mode;该字段仅保留在 legacy persistence snapshot / compatibility scope。
更新字段审核
PATCH /document-recognition/runs/{run_id}/field-reviews/{field_id}
Content-Type: application/json
支持的 review_status:
pendingacceptedcorrectedflagged
请求体还允许附带可选 reviewer_identity 展示型快照;当字段值、审核状态或 reviewer note 实际发生变化时,服务端会追加一条 revision ledger。
读取单字段历史
GET /document-recognition/runs/{run_id}/field-reviews/{field_id}/revisions
该接口返回 baseline、当前态与 append-only revisions[]。对于功能上线前没有 ledger 的旧 run,响应会显式标记 history_status=unrecorded。
下载识别资产
GET /document-recognition/runs/{run_id}/source-document
GET /document-recognition/runs/{run_id}/source-pdf
GET /document-recognition/runs/{run_id}/result
管理可选 Fusion agent
GET /admin/document-recognition/runtime-agents
PUT /admin/document-recognition/runtime-agents/{agent_id}
DELETE /admin/document-recognition/runtime-agents/{agent_id}
管理端 registry 用来显式声明哪些 Fusion agent 可以被 document recognition 消费;未注册 agent 的 run 不会进入 /document-recognition/runs*。
Admin 概览与队列
GET /admin/document-recognition/overview
GET /admin/document-recognition/runs
Admin 端可以按 status、document_type、review_status 过滤。
文件存储路径
| 文件类型 | MinIO 路径 |
|---|---|
| 源单证 | document_extraction/{agent_id}/{job_id}/source/{filename} |
| 结果 JSON | document_extraction/{agent_id}/{job_id}/output/result.json |
前端职责划分
demo-frontend:主审核工作台,进入document_extractionAgent 时切换到独立Document Recognition Console,负责输入、预览、字段审核、轮询刷新admin-frontend:运营控制台,负责概览、队列、详情、跳转到 Demo 工作台
这种分工可以保证高频字段编辑不挤进 Admin 主控制台,同时让 Admin 保持监控与检索效率。
前端回归记录
2026-03-23: 字段审核队列塌缩成细线
症状:
Field queue中的字段并没有丢失,DOM 和文本仍然存在。- UI 上看起来却像只剩下一条条细线,展开态编辑器也像“塌”进去了。
- 硬刷新通常无效,因为问题来自布局收缩,不是数据状态缺失。
示例截图:
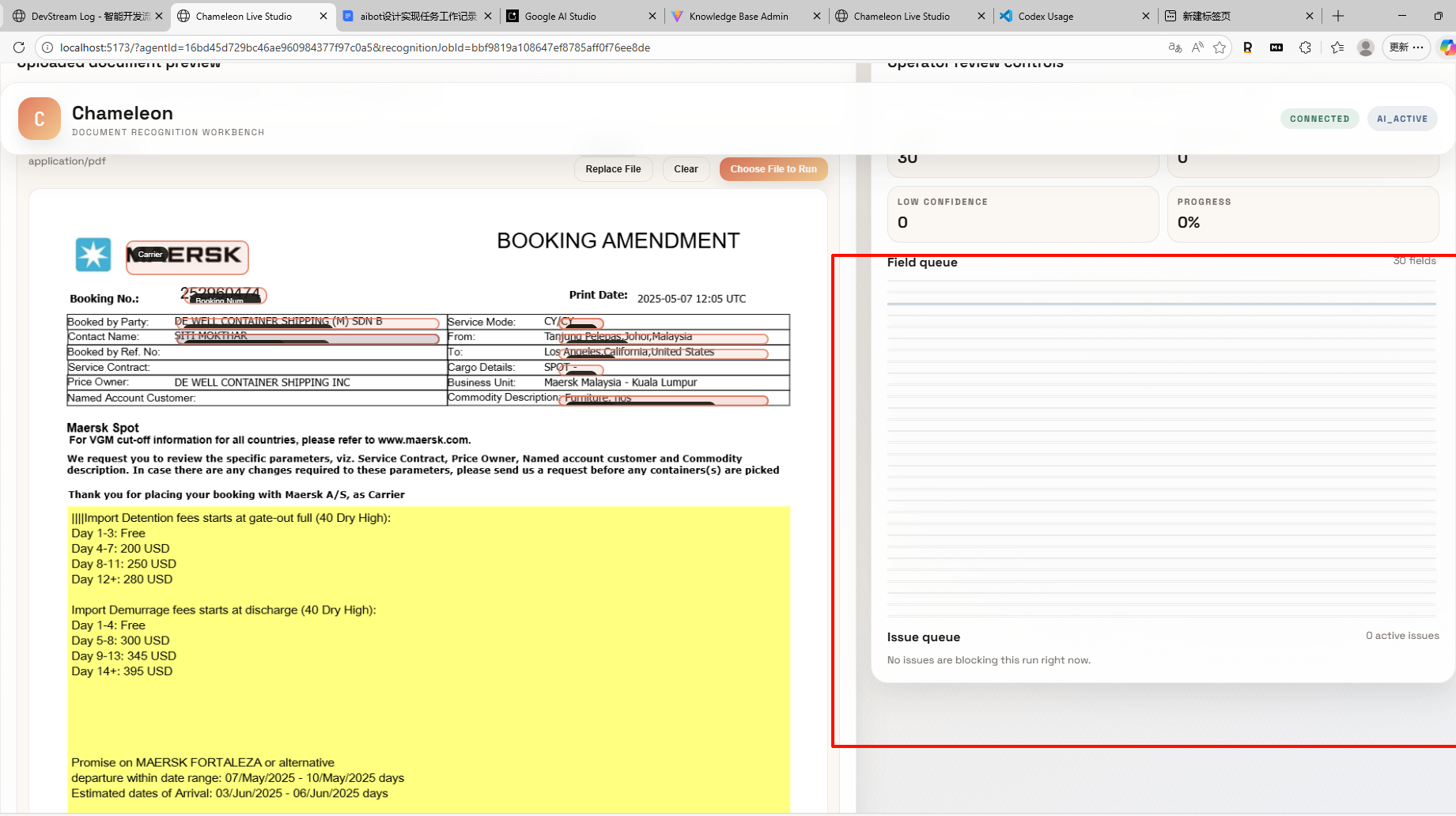
上图中的红框区域就是这次回归的典型表现:字段内容仍在页面里,但父卡片高度被压扁后,视觉上只剩下边框线。
真实根因:
RecognitionReviewPanel.jsx把字段审核队列做成了带max-height: 460px的纵向滚动容器。- 队列里字段很多时,
.recognition-field-item作为 flex item 使用了默认的flex-shrink: 1。 - 结果不是内部内容没渲染,而是父卡片高度被压缩到几像素,只剩边框可见;子节点文本和编辑器仍然在 DOM 里。
修复与约束:
demo-frontend/src/components/RecognitionReviewPanel.jsx和demo-frontend/src/styles.css都要显式保留.recognition-field-item的flex-shrink: 0。- 以后只要字段卡片放进“有界高度 + 纵向 flex 滚动”的队列,就不能依赖默认 shrink 行为。
- 需要“一行一个字段并可直接在该行展开编辑”时,保持“行内容 + 行内编辑器”的结构,不要再回退到会让父卡片参与收缩的布局。
排查信号:
- 如果字段文本能在 DevTools 里看到,但
.recognition-field-item高度只有几像素,而内部 toggle/editor 高度正常,优先检查 flex shrink。 recognitionJobId的 URL 恢复竞态会影响默认打开哪个任务,但那是独立问题,不是这次“细线塌缩”的根因。